
Joonas' Note
[딥러닝 일지] Conv2d 알아보기 본문
이전 글 - [딥러닝 일지] 데이터 늘리기 (Data Augmentation)
Convolution 2D
이미지를 다루는 딥러닝에서 핵심적인 요소로 쓰이고 있다. 이걸 쌓은 네트워크가 CNN.
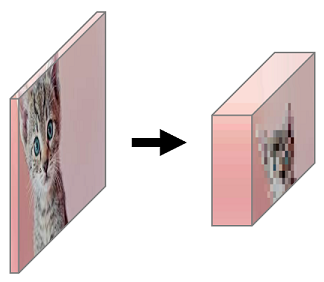
학습 데이터로 들어가는 텐서는 아래와 같이 벡터 덩어리(?)의 모습이므로, 오른쪽의 RGB 이미지도 왼쪽과 같은 (3, 4, 4) 크기의 텐서가 된다.
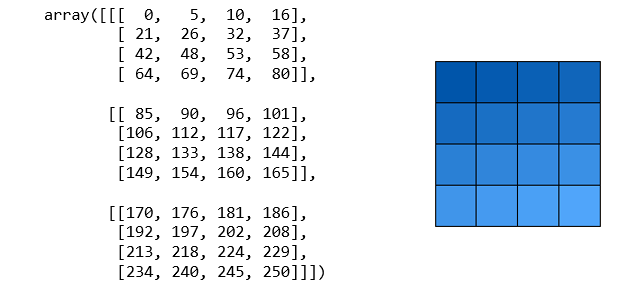
하지만 같은 이미지를 조금만 회전해도 배열의 순서가 완전히 다른 모습이 되기 때문에, 학습하려는 그래프의 입장에서는 의미있는 특징(feature)들을 뽑아내기 힘들어진다.

이미지는 그 특성상, 인접한 픽셀끼리 뭉쳐서 해석하는 것이 어떤 의미를 가질 수 있다고 생각한 접근이 아닐까한다.
필터, 커널
그렇다면 덩어리 단위로 묶어주는 작업이 필요한데, 이것은 슬라이딩 윈도우 기법과 동일하다.
실제로는 하나의 채널에 대해서 처리하지만, 예시를 들면 이러하다.

이렇게 픽셀을 어떻게 뭉쳐서 볼 것인지 결정하는 윈도우를 필터(filter) 또는 커널(kernel)이라고 부르는 것 같다.
아래 GIF가 이해에 많이 도움이 된다.
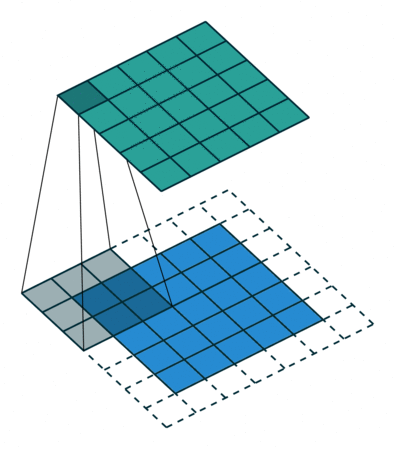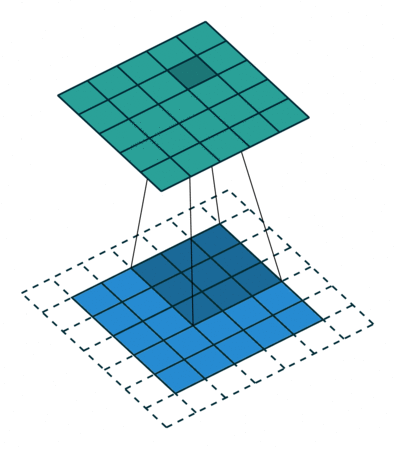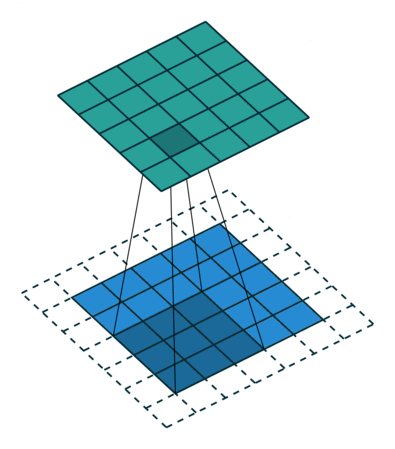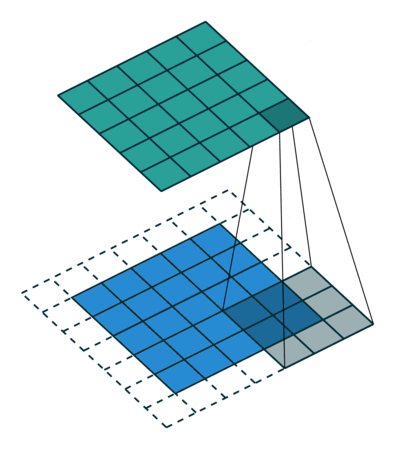
합성곱 계층, Convolution Layer
합성곱 신경망, Convolutional Neural Network (CNN) 완전 연결 계층, Fully connected layer (JY) Keras 사용해보기 1. What is keras? 케라스(Keras)는 텐서플로우 라이버러리 중 하나로, 딥러닝 모델 설계와 훈..
dsbook.tistory.com
위 링크의 글에서 padding과 stride에 대한 설명도 볼 수 있다.
아무튼 이러한 특징때문에 kernel size, padding, stride에 따라 텐서의 크기가 변할 수 있다.
PyTorch에서는 이 작업을 해주는 모듈 nn.conv2d가 있다.
nn.conv2d
그럼, CNN 그림에서 자주 보이는 이건 무슨 의미일까?
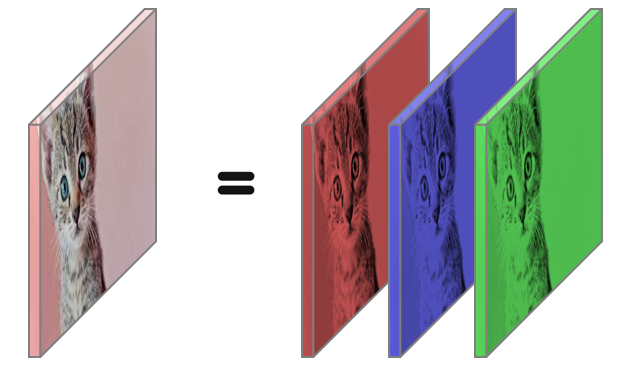
필터는 한 채널에 대해서 작업한다. 그러니까 위 이미지는 RGB 3개의 채널을 가지고 있다.
예를 들어, 고양이 이미지의 크기가 (100, 100) 이라면, RGB 3채널이므로 (3, 100, 100) 이라는 뜻이다.
nn.conv2d는 파라미터로 in_channels와 out_channels가 들어간다.
만약 in_channels가 3이라면, 3채널인 RGB가 각각 들어간다는 뜻이고, out_channels 만큼의 필터링 결과를 뽑아낸다.
즉, 3개가 쌓여있던 채널이 conv2d를 거치면 out_channels만큼의 채널이 되므로 두께가 두꺼워지게 그리는 것이다.

내부적으로 입력에 따라 몇 개의 필터를 사용하는 지는 모르겠지만, nn.conv2d 문서에서는 groups라는 파라미터로 이를 설정할 수 있는 것 같다.
Pooling
Pooling은 convolution으로 뽑아낸 값을 전부 가져가는 것이 아니라, 대표적인 특징만 남기는 작업이다.
많이 쓰이는 것은 MaxPooling으로 지정한 kernel만큼 훑으면서 가장 큰 값만 남기는 것이다.
모든 칸에 대해서 훑으면 크기가 그대로겠지만, 건너뛰는 값인 stride에 따라 이미지의 크기가 줄어든다.

위 GIF처럼 stride를 2로 잡고 모든 채널마다 MaxPool을 적용하면, 128x128 크기의 RGB이미지는 (3, 128, 128)에서 (3, 64, 64)가 될 것이다.
마무리
CNN에서 사용하는 block은 보통 아래와 같다.

정확히는 conv2d와 maxpool 사이에 activation 함수(Sigmoid, ReLU 등)이 들어간다.
(conv2d+activation+maxpool) 이렇게를 한 block으로 묶어서 이 conv2d block을 여러번 반복하면, 최종적으로 우리가 자주 보는 아래의 그림이 되는 것이다.

'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝 일지] MNIST Competition (0) | 2022.03.31 |
|---|---|
| [딥러닝 일지] 오프라인에서 파이토치 모델 불러오기 (0) | 2022.03.29 |
| [딥러닝 일지] 데이터 늘리기 (Data Augmentation) (2) | 2022.03.25 |
| [딥러닝 일지] 이미지 가지고 놀기 (변환하기) (8) | 2022.03.24 |
| [딥러닝 일지] 다른 모델도 써보기 (Transfer Learning) (0) | 2022.03.13 |



