
Joonas' Note
[딥러닝 일지] MNIST Competition 본문
이전 글 - [딥러닝 일지] 오프라인에서 파이토치 모델 불러오기
MNIST
공부한 CNN을 토대로 참가해볼만한 competition이 없을까 찾아보다가 계속 Ongoing 중인 것을 찾았다.
https://www.kaggle.com/competitions/digit-recognizer
데이터가 예상과 다르게 생겨서 당황했었다. jpg나 png 이미지 파일로 있을 줄 알았는데 csv 형태였고, (28, 28) 사이즈의 픽셀을 전부 column으로 들고 있었다.
VGG16 실패
이전의 글에서 했던 것 처럼, VGG16 뒤에 FC 레이어를 붙여서 학습해봤는데 18+시간이 걸렸다. 가지고 있던 gpu 할당 시간을 초과해서 학습이 그대로 끝나있었다.
VGG16은 (3, 224, 224) 크기의 이미지를 입력으로 쓰고 있어서 앞쪽에 이미지를 scale up 하는 작업을 붙였었는데 그게 아주 오래 걸린 듯 하다.
특히 이 데이터셋은 4만장이라서, 개와 고양이(2만장)를 할 때와는 많이 다르게 오래 걸렸다.
더 작은 ConvNet
MNIST 데이터 셋은 (28, 28) 사이즈에 흑백으로 1채널이다. 그러니 굳이 (3, 224, 224) 사이즈로 맞춰서 1000개 클래스의 output을 내는 것은 닭 잡는 데 소 잡는 칼인 격이다.
(3, 28, 28) 이미지를 받아서 10개의 클래스만 뽑아내는 모델을 직접 작성했다.
간단하게 conv2d 블럭은 3개 정도만 쌓았다.
크기 변화는 (3, 28, 28) → (16, 28, 28) → (16, 14, 14) → (64, 14, 14) → (64, 7, 7) → (128, 3, 3) 순으로 변한다.
class MyConvNet(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), padding=1),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Conv2d(16, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 5),
nn.ReLU(),
)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(3 * 3 * 128, 512),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(512, 128),
nn.Linear(128, 10),
)
def forward(self, x):
x = self.layer(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x이렇게 모델을 바꿨더니 12시간 넘게 걸리던 것이 1시간 반만에 학습이 끝났다.
필요없는 전처리 제거
def bin_to_rgb(t):
h, w = t.shape
img = np.array([np.array(t).reshape(1, h, w)] * 3).reshape(3, h, w).astype(np.float32)
return torch.tensor(img)
train_set = DigitDataset(train_df, transform=transforms.Compose([
bin_to_rgb,
transforms.ToPILImage(),
transforms.Resize(56),
transforms.RandomRotation(20),
transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.3, 5)),
transforms.Resize(28), # 원래 224 였음
transforms.ToTensor(),
normalize,
]))
3채널로 들어가야해서, 단순히 (x) → (x, x, x) 로 채널을 3개로 늘리는 작업을 해줬고, PIL Image로 바꿔서 크기로 조정했다.
train set에는 변형을 조금 주고 싶어서, RandomRotation이랑 GaussianBlur도 넣었는데 이게 오히려 독이었다.
같은 숫자여도 데이터 자체가 조금씩 돌아가있어서, 10도 정도만 살짝 돌리는 작업은 굳이 필요 없었고,
가우시안 블러는 5나 8, 9 같은 숫자들을 오히려 더 뭉치게 만들어서 학습을 힘들게 만들었다.
train_set = DigitDataset(train_df, transform=transforms.Compose([
bin_to_rgb,
normalize,
]))
이렇게만 해줬는데도 정확도가 97.36% → 98.65% (+1.3%) 로 올라갔다. (Version 7)
그리고 속도는 더 빨라졌다. 같은 모델에서 1시간 반 걸리던 것이 20분 정도로 훅 줄었다.
하이퍼파라미터 튜닝
Version 7에서 학습된 모양새가 영 찜찜했다.

그래서 한번 더 학습을 돌리면서, 이번에는 50 에포크까지 돌렸다. (Version 8)
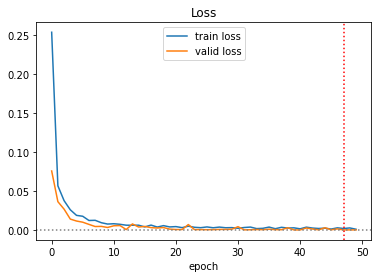
아무래도 에포크와 상관없이 랜덤에 의해서 더 잘 학습된 것이 아닐까한다.
결과는 99.042%
학습 중간에 valid set으로 loss/accuracy를 체크해봤는데, 뒤로 갈수록 loss가 0.000014도 나오고그래서 너무 과적합되는게 아닌가 하는 걱정이 있었다.
그래서 모델을 조금 수정했다. (Version 11) Conv2d 사이마다 BatchNorm2d를 넣어봤다. 그리고 다시 30 에포크로 줄였다. 그 결과는,

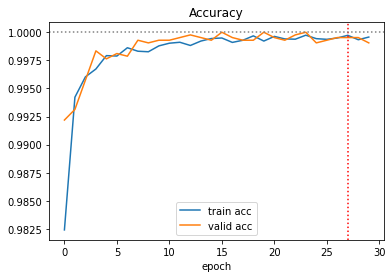
정확도를 99.446%까지 올리면서 마무리했다.

마무리
Competition에 참가하면서 점수도 점점 높여가면서, 랭킹도 올리는 것이 재밌었다.

이 MINST competition의 경우에는 Rolling Leaderboard 방식인데, 참가한 지 2주가 지난 사람들은 랭킹에서 빠지는 방식이다. 고인물은 퍼내고 새로 시작하는 유입들에겐 재미를 줄 수 있는 좋은 컨셉같다.
'AI > 딥러닝' 카테고리의 다른 글
| [PyTorch] AssertionError: Torch not compiled with CUDA enabled (0) | 2022.05.30 |
|---|---|
| [PyTorch] GPU 메모리가 부족할 때 확인할 내용들 (0) | 2022.04.25 |
| [딥러닝 일지] 오프라인에서 파이토치 모델 불러오기 (0) | 2022.03.29 |
| [딥러닝 일지] Conv2d 알아보기 (0) | 2022.03.26 |
| [딥러닝 일지] 데이터 늘리기 (Data Augmentation) (2) | 2022.03.25 |


